
HISTORIA
BIOGRAFÍA
Karl Ludwig von Bertalanffy (nacido el 19 de septiembre de 1901 en Viena, Austria y fallecido el 12 de junio de 1972 en Bufalo, Nueva York, Estados Unidos) fue un biólogo y filósofo austríaco, reconocido fundamentalmente por su teoría de sistemas.
Venía de ancestros nobles de Hungría. Estudió con tutores personales en su propia casa hasta sus 10 años. Ingresó en la Universidad de Innsbruck para estudiar historia del arte, filosofía y biología, finalizando su doctorado en 1926[4] con una tesis doctoral sobre psicofísica y Gustav Fechner. En 1937 fue a vivir a Estados Unidos gracias a la obtención de una beca de la Fundación Rockefeller, donde permaneció dos años en la Universidad de Chicago, tras los cuales vuelve a Europa por no querer aceptar declararse víctima del nazismo. En 1939 trabajó como profesor en la Universidad de Viena, donde permaneció hasta 1948. Al año siguiente emigra a Canadá para continuar sus investigaciones en la Universidad de Ottawa hasta 1954. Después se traslada a Los Ángeles para trabajar en el Mount Sinai Hospital desde 1955 hasta 1958. Impartió clases de biología teórica en la Universidad de Alberta en Edmonton, Canadá, de 1961 a 1969. Desde esa fecha y hasta su fallecimiento trabajó como profesor en el Centro de biología Teórica de la Universidad Estatal de Nueva York en Búfalo. Ludwing Von Bertalanffy murió el 12 de junio de 1972 en Búfalo, Estados Unidos.
TEORÍA DE SISTEMAS
La Teoría General de Sistemas fue, en origen una concepción totalizadora de la biología (denominada "organicista"), bajo la que se conceptualizaba al organismo como un sistema abierto, en constante intercambio con otros sistemas circundantes por medio de complejas interacciones. Esta concepción dentro de una Teoría General de la Biología fue la base para su Teoría General de los Sistemas. Bertalanffy leyó un primer esbozo de su teoría en un seminario de Charles Morris en la Universidad de Chicago en 1937, para desarrollarla progresivamente en distintas conferencias dictadas en Viena. La publicación sistemática de sus ideas se tuvo que posponer a causa del final de la Segunda Guerra Mundial, pero acabó cristalizando con la publicación, en 1969 de su libro titulado, precisamente Teoría General de Sistemas. Von Bertalanffy utilizó los principios allí expuestos para explorar y explicar temas científicos y filosóficos, incluyendo una concepción humanista de la naturaleza humana, opuesta a la concepción mecanicista y robótica.
CONCEPTOS
A traves de la historia se han utlizado la simulacion, desde la imitacion de los sonidos onomatopeyo ya que la simulación es la recreacion o reproduccion de un sistema sin llevarlo a la realidad implicando la imitacion, engaño, trampa para sustentar un sistema real, para llevar a cabo este proceso se cuenta con la yuda de la herramienta computacional. Por eso acontinuacion se hace referencia a ella.
A medidad que no enfretamos a algunos problemas del mundo real, el modelo resultante puede ser tan complejo o grande que no es posible o práctico desarrollar de esta manera nuestros recursos humanos se hacen imposible recrear en donde procedemos a la simulacion por computadora. Una metodología de solución basada en un análisis matemático. De manera alternativa, aplicar una técnica matemática existente puede requerir supuestos adicionales que no son aplicables o realistas.
En tales casos, un enfoque alternativo sería usar una técnica de la Ciencia Informática: la simulación por computadora. Como el término indica, con esta técnica, usted diseña y construye un modelo de computadora que imita el argumento real del problema. Entonces usa el modelo para aprender cómo se comporta el sistema, formulándose preguntas del tipo: "¿qué sucedería si...?”.
Por ejemplo, podría construir un modelo de computadora para simular lo siguiente:
La operación diaria de un banco u hospital, para comprender el impacto de añadir más pagadores o enfermeras.
La operación de un puerto marítimo o aéreo, para comprender el flujo de tráfico, y su congestión asociada.
El proceso de producción en una fábrica, para identificar los cuellos de botella en línea de producción.
El flujo de tráfico en una autopista en un sistema de comunicación complicado, para determinar si es necesaria una expansión.
La simulación implica un acto de engaño ya que reproduce la realidad sin ser la realidad, se considera una técnica no una ciencia, para que se efectúe la simulación, debe haber decisión.
La simulación se clasifica en:
1. Según el tiempo:
- Proyectiva: es la que muestra patrones de comportamientos de un sistema en el futuro, es decir de un hecho o situación que no se ha vivido, este tipo de simulación ayuda a medir impactos y es de gran utilidad en proyectos de transporte fluvial, terrestre y en la industria aeroespacial, por ejemplo la trayectoria de un proyectil.
- Retrospectiva: es la que reproduce situaciones del pasado, lo reconstruye, por ejemplo la reconstrucción del titanic.
2. Según el medio ambiente:
- Seminmersiva: es aquella donde el sujeto participa del sistema pero no está dentro, por ejemplo, el nintendo wii.
- Inmersiva: en esta, el sujeto participa dentro del sistema, interactúa en el interior de la simulación.
- Realidad virtual: es la simulación en la cual se ve cosas muy reales pero no se está dentro del sistema.
- Realidad virtual Inmersiva: en esta se ve cosas, se palpan y se interactúa con ellas, por ejemplo, la industria erótica ofrece un servicio llamado ciberorgasmo.
- Externa: el sujeto esta fuera del objeto de simulación, no interactúa con el sistema de manera interna, por ejemplo, los videojuegos que están ligados con el animatronic.
Las clases de simulación más comunes en la realidad son la seminmersiva, la Inmersiva y la realidad virtual.
Según los detractores la simulación no ofrece gran beneficio, debido a que es un ambiente netamente especulativo, mientras que la experimentación es una técnica mas real; mientras que las personas que están a favor aseguran que la simulación implica reproducir una realidad sin necesidad de hacerla real; sin embargo, es importante aseverar que la simulación le gana a la experimentación cuando la variable costo es menor que la experimentación.
La simulación recrea la realidad a través de la Teoría General de Sistema, con la cual se estudia la realidad por medio de los sistemas, los cuales se componen de variables.
El hombre debe observar el comportamiento del sistema con el fin de simplificar las variables caracterizándolas según su grado de prioridad y significancia para el sistema global; esta valoración es hecha por el modelador el cual identifica el tipo de relación; las más comunes son las lineales (directas), las diferentes (inversas) e indiferentes (no existe relación).
El modelador tiene la función de identificar las variables críticas y su relación, siempre y cuando existan.

Fuente imagen realizada por Martha Pulido
Las variables pueden ser discretas o continuas según el tiempo; y se pueden clasificar de igual forma en cuantitativas (se mide con patrones numéricos) y en cualitativas (no se mide con patrones numéricos), sin embargo todas las variables terminan cuantitativas. A partir de la variable cuantitativa o cualitativa, se sustrae la información de ellas y esta se ordena con la estadística.
Una variable es un fenómeno que puede tomar diferentes estados, ese fenómeno es de igual forma una variable, por ejemplo:
Variable: clima
Fenómeno: lluvioso, nublado, soleado (de igual forma son variables)
Es importante resaltar que la interpretación de los signos y síntomas de un sistema se da por medio de la observación.
MODULO ESTADISTICO
La estadística puede ser de 2 tipos:
· Descriptiva: sirve para describir y detallar el sistema
· Inferencia: sirve para inferir o predecir el sistema
La estadística descriptiva se utiliza para caracterizar estadísticamente, es decir, visualizar datos.
Prueba de bondad e ajuste: determina si los datos observados se ajustan a un modelo estadístico previamente conocido.
Conceptos estadísticos de medida de tendencia central
- Media: es el aporte equitativo o uniforme de cada uno de los números en cuanto al aporte totalizado, políticamente hablando sería una medida comunista, porque intenta aportar a todos por iguales.
- Moda: es el valor que más se repite, no necesariamente tiene la verdad, políticamente sería una medida democrática
- Mediana: es una medida de posición, es el valor que está en la mitad.
Existen ciertas medidas de error, que son:
- Rango: es el intervalo del grupo de datos, el cual se halla restando el valor maximo menos el valor minimo.
- Desviación: este se halla con respecto a la media, donde se le resta a cada uno de los datos, calculando de esta forma el error.
CLASIFICACION DE LOS SISTEMAS
HISTOGRAMA
Un histograma es una gráfica de barras que nos permite describir el comportamiento de un conjunto de datos, pero en este caso las diferentes observaciones de una misma variable se grafican alrededor de un valor medio o central.
Algunos de los usos más comunes del uso de un histograma son: aumentar la calidad de algunos procesos, pues todos sabemos que es necesario reducir al mínimo la variación que se presente en el mismo. Es por eso, que el histograma nos permite identificar cuantas veces se repite un mismo valor, así como la frecuencia con la que se presenta. Siendo base para la toma de decisiones.
Fuente: http://www.herramientasparapymes.com/que-es-histograma-y-como-crear-un-histograma-en-excel
INSTRUCTIVO HISTOGRAMA
PRUEBA DE HIPÓTESIS CHI CUADRADO O BONDAD DE AJUSTE
Hasta ahora se han mencionado formas de probar lo que se puede llamar hipótesis paramétricas con relación a una variable aleatoria, o sea que se ha supuesto que se conoce la ley de probabilidad y se vieron pruebas de hipótesis que declaran valores para los parámetros. En algunos casos se necesita probar si una variable o unos datos siguen determinada distribución de probabilidad, un método para hacer esta prueba es el de bondad de ajuste o chi-cuadrado.
La información debe estar presentada en un cuadro de distribución de frecuencias. Sea m el número de clases y nj el número de observaciones en cada clase (frecuencias observadas). Se trata de comparar los valores o frecuencias observadas (nj ) con las frecuencias que habría en cada grupo o clase o sea el valor esperado (ej ) si se cumple la hipótesis nula (H0 ).
La información debe estar presentada en un cuadro de distribución de frecuencias. Sea m el número de clases y nj el número de observaciones en cada clase (frecuencias observadas). Se trata de comparar los valores o frecuencias observadas (nj ) con las frecuencias que habría en cada grupo o clase o sea el valor esperado (ej ) si se cumple la hipótesis nula (H0 ).
3. Las diferencias entre lo observado y lo esperado dan las discrepancias entre la teoría y la realidad. Si no hay diferencias, la realidad coincidirá perfectamente con la teoría y por el contrario, si las diferencias son grandes indica que la realidad y la teoría no se parecen.
4. Declaración de hipótesis:
H0 : La variable tiene distribución X con ciertos parámetros
H1 : La variable no tiene la distribución X
nj : frecuencia observada en la muestra
ej : frecuencia esperada según la distribución teórica
n: tamaño de la muestra
Nota. El número de observaciones esperadas en cada clase debe ser mayor o igual a 5, es decir, ej
Fuente: http://www.virtual.unal.edu.co
INSTRUCTIVO BONDAD DE AJUSTE DISTRIBUCIÓN NORMAL Y UNIFORME CHI CUADRADO
Descargar Instructivo Chi Cuadrado
EJERCICIO BONDAD DE AJUSTE DISTRIBUCIÓN NORMAL CHI CUADRADO
Descargar Ejercicio Chi Cuadrado Normal
EJERCICIO BONDAD DE AJUSTE DISTRIBUCIÓN UNIFORME CHI CUADRADO
Descargar Ejercicio Chi Cuadrado Uniforme
EJERCICIO BONDAD DE AJUSTE DISTRIBUCIÓN NORMAL CHI CUADRADO
Descargar Ejercicio Chi Cuadrado Normal
EJERCICIO BONDAD DE AJUSTE DISTRIBUCIÓN UNIFORME CHI CUADRADO
Descargar Ejercicio Chi Cuadrado Uniforme
VÍDEO EJERCICIO BONDAD DE AJUSTE DISTRIBUCION UNIFORME CHI CUADRADO
VIDEO EJERCICIO BONDAD DE AJUSTE DISTRIBUCION NORMAL CHI CUADRADO
PRUEBA DE BONDAD DE AJUSTE SMIRNOV-KOLMOGOROV
La prueba de Kolmogorov-Smirnov para una muestra se considera un procedimiento de "bondad de ajuste", es decir, permite medir el grado de concordancia existente entre la distribución de un conjunto de datos y una distribución teórica específica. Su objetivo es señalar si los datos provienen de una población que tiene la distribución teórica especificada.
Mediante la prueba se compara la distribución acumulada de las frecuencias teóricas (ft) con la distribución acumulada de las frecuencias observadas (fo), se encuentra el punto de divergencia máxima y se determina qué probabilidad existe de que una diferencia de esa magnitud se deba al azar.
PASOS:
- Calcular las frecuencias esperadas de la distribución teórica específica por considerar para determinado número de clases, en un arreglo de rangos de menor a mayor.
- Arreglar estos valores teóricos en frecuencias acumuladas.
- Arreglar acumulativamente las frecuencias relativas.
- Aplicar la ecuación D = ft - f obs, donde D es la máxima discrepancia de ambas.
- Comparar el valor estadístico D de Kolmogorov-Smirnov en la tabla de valores críticos de D, teniendo en cuenta el grado de libertad y el nivel de significancia.
- Decidir si se acepta o rechaza la hipótesis.
- Si se acepta “no hay suficiente evidencia estadística para decir que los datos observados no se ajusten al modelo”
No se acepta ”o hay suficiente evidencia estadística para decir que los datos observados se ajusten al modelo”
Planteamiento de la hipótesis.
- Hipótesis alterna (Ha). Los valores observados de las frecuencias para cada clase son diferentes de las frecuencias teóricas de una distribución normal.
- Hipótesis nula (Ho). Las diferencias entre los valores observados y los teóricos de la distribución normal se deben al azar.
Nivel de significación.
Se le denomina nivel de riesgo porque eventualmente se corre el riesgo de tomar una probabilidad nula cuando esta es verdadera.
Se le denomina nivel de riesgo porque eventualmente se corre el riesgo de tomar una probabilidad nula cuando esta es verdadera.
Para todo valor de probabilidad igual o menor que 0.05, se acepta Ha y se rechaza Ho.
Zona de rechazo.
Para todo valor de probabilidad mayor que 0.05, se acepta Ho y se rechaza Ha.
En el caso del ejercicio de uso la tercera ecuación ya que el nivel de significancia es igual a 0.05.
INSTRUCTIVO BONDAD DE AJUSTE NORMAL SMIRNOV KOMOGOROV
EJERCICIO PRUEBA DE BONDAD DE AJUSTE SMIRNOV KOLMOGOROV NORMAL Y UNIFORME
VÍDEO EJERCICIO BONDAD DE AJUSTE DISTRIBUCION UNIFORME SMIRNOV KOLMOGOROV
PRUEBA DE BONDAD DE AJUSTE ANDERSON DARLING
La prueba de Anderson-Darling es usada para probar si una muestra viene de una distribución especifica. Esta prueba es una modificación de la prueba de Kolmogorov- Smirnov donde se le da más peso a las colas de la distribución que la prueba de Kolmogorov-Smirnov.
En estadística, la prueba de Anderson-Darling es una prueba no paramétrica sobre si los datos de una muestra provienen de una distribución específica. La fórmula para el estadístico determina si los datos (observar que los datos se deben ordenar) vienen de una distribución con función acumulativaF .
Formulas:
A2= − N− S
Donde:


El estadístico de la prueba se puede entonces comparar contra las distribuciones del estadístico de prueba (dependiendo que se utiliza) para determinar el P- valor.
INSTRUCTIVO DEL TEST DE ANDERSON DARLING
PLANTILLA DE EJERCICIO EN EXCEL DE ANDERSON DARLING
VIDEO EJERCICIO ANDERSON DARLING
MODULO DE SIMULACIÓN
Salida: es el objetivo de un estudio de simulación que tiene la forma de un valor numérico específico.
Entrada: es un valor numérico que es necesario para determinar las salidas de una simulación
Antes de diseñar los detalles de una simulación por computadora es decisivo tener una clara comprensión de los objetivos del estudio en la forma de salidas numéricas específicas. Con las salidas identificadas, el siguiente paso es identificar las entradas.
DISEÑO DE LA SIMULACIÓN POR COMPUTADORA.
Una vez que se hayan identificado las salidas y las entradas necesarias, la simulación real consiste en generar números aleatorios y en la contabilidad.
Paso 1: Generación de números aleatorios: consiste en obtener las entradas probabilísticas para el modelo generando números aleatorios de acuerdo con las distribuciones conocidas asociadas.
Paso 2: consiste en el diseño de un método sistemático para almacenar y procesar todos los valores de entrada y para realizar los cálculos necesarios para obtener los valores de salida.
GENERACIÓN DE NÚMEROS ALEATORIOS.
Todos los lenguajes de computadora usados para desarrollar simulaciones tienen una capacidad incluida de generar una serie de números aleatorios entre 0 y 1 en la que se cumple lo siguiente:
El enfoque se basa en métodos numéricos.
La serie específica depende de un valor inicial proporcionado por el usuario llamado semilla.
Para una semilla particular, la serie está determinada. Cada vez que se usa esa misma semilla se genera la misma serie de números aleatorios. Los números generados satisfacen las siguientes propiedades:
Para una semilla particular, la serie está determinada. Cada vez que se usa esa misma semilla se genera la misma serie de números aleatorios. Los números generados satisfacen las siguientes propiedades:
a. Están uniformemente distribuidos entre 0 y 1; y
b. Los números sucesivos son estadísticamente independientes entre si.
Como resultado, aunque la semilla determina la serie precisa de números, estos obedecen las propiedades estadísticas deseadas de los números aleatorios 0 - 1. Por consiguiente se denominan números seudoaleatorios.
Aquí podemos observar como los números aleatorios son tan exacto como el la ruleta de Monte Carlos.
LENGUAJES DE PROGRAMACIÓN DE SIMULACIÓN.
El que la simulación comprenda cómputos numéricos conduce en forma natural a utilizar computadoras digitales, al grado que se han diseñado muchos lenguajes de programación para realizar simulaciones. Por lo general esos lenguajes dan al usuario un conjunto de concepto de modelado que se utilizan para describir el sistema y un sistema de programación que convierta la descripción a programa de computadora, que ejecute la simulación. En consecuencia, se libera al usuario de mucho esfuerzo de programación detallada, especialmente en el caso de programas de simulación discreta en que puede complicarse demasiado la tarea de administrar los pagos lógicos que participan en los eventos que se ejecutan.
FUENTE: http://www.dei.uc.edu.py/tai99/introsimulacion/simucon.html;
conceptualizado por ingeniero Medardo Gonzalez y transcrito por los estudiante de IX semestre de Ingenieria industrial Universidad Libre Barranquilla.
conceptualizado por ingeniero Medardo Gonzalez y transcrito por los estudiante de IX semestre de Ingenieria industrial Universidad Libre Barranquilla.
INSTRUCTIVO EJERCICIO SIMULACIÓN
Descargar Instructivo Ejercicio de Simulación
GENERACION DE NUMEROS PSEUDOALEATORIOS
Aleatorios: el azar es una consecuencia de la aleatoriedad, la cual parte de un conjunto de números que pueden suceder.
Un dado con 6 caras, se vuelve aleatorio cuando cada una de las caras tiene la misma probabilidad de ocurrencia. No hay nada para predecir su comportamiento, y si se encuentra un método deja de ser aleatorio (métodos estadísticos de caracterización de números de datos).
Tiene como característica principal, números entre 0 y 1 [(0 1)], pero que nunca son ni 0 ni 1, por esto se le denominan pseudoaleatorios.
La aleatoriedad está ligada con la probabilidad, sin embargo la diferencia consiste en que los números están entre 0 y 1 pero incluye el concepto de igualdad [0≤X≤1]
Los aleatorios están gobernados por la distribución uniforme, porque existe Ay B, y entre ellos se halla la misma probabilidad de ocurrencia.


fuente: imagen elaborada por Martha Pulido
Como la simulación implica engaño, se debe tener métodos para la simulación de números aleatorios, los más conocidos son:
a) Métodos mecánicos: se creó la ruleta, pero surgieron ciertos inconvenientes como la poca flexibilidad de transporte y que resultaba ser poco equitativa, la más justa es la ruleta del principado de Montecarlo
b) Métodos por señales eléctricas: las señales eléctricas tienen un comportamiento llamado Movimiento Armónico Simple (M.A.S.), con el cual se medían en puntos diferentes del recorrido de la señal eléctrica, la cual oscilaba entre 1 y -1.

fuente: imagen elaborada por Martha Pulido
c) Métodos de cuadrados medios: se toma un valor de 4 números, este se llama semilla, se eleva al cuadrado, lo cual da como resultado 8 números, tomamos los 4 de la mitad y se divide entre 10000 para que arroje un numero entre 0 y 1, es decir la probabilidad, luego al número compuesto por 4 cifras se eleva al cuadrado, y así consecutivamente, generando una serie de números aleatorios por ejemplo:

fuente: imagen elaborada por Martha Pulido
En Excel, primero se pone el número, luego se eleva al cuadrado y después se toman los 4 números de la mitad de la siguiente manera:

Luego, se arrastran las columnas, y esto va generando una serie de números aleatorios, sin embargo este número debe dividirse entre 10000 para que se produzcan entre 0 y 1:

Este método no es tan confiable, muchas veces puede aparecer la semilla mala, es decir, cuando converge en 0, convirtiéndolo en predecible, por ello Lehmer se ideo el método congruencial.
d) Métodos congruenciales: este método tiene 3 variantes que son los congruenciales aditivos, multiplicativos y los mixtos.
El resultado de la formula de Lehmer depende de un factor aditivo a mas un factor multiplicativo b Xn y se le saca el modulo m, es decir:

fuente: imagen elaborada por Martha Pulido
Esta es la fórmula que aplica las calculadoras en la función Ran# ( la mixta).

Rand Corporation es una empresa que existió y desarrollo el RanD (Research and Development), usada por la milicia como contrainteligencia en la II guerra mundial y John Nash trabajo con la Rand Corporation para descifrar los códigos que mandaban los alemanes por medio de la maquina enigma, la cual trabajaba con un cifrado rotario. Alan Turing fue el que descifro los mensajes secretos de la maquina enigma, este ingles lo hizo por mecanización de preguntas hipotéticas y usaban el método congruencial.
En Excel:

PROPIEDADES MINIMAS QUE DEBEN SATISFACER LOS NUMEROS PSEUDOALEATORIOS
*Ajustarse a una distribuciónU(0,1).
*tener una media aproximada de 1/2
*contar con una varianza aproximada de 1/12
*Ser estadísticamente independientes (no debe deducirse un número
conociendo otros ya generados).
*Ser reproducibles (la misma semilla debe dar la misma sucesión).
*Ciclo repetitivo muy largo.
*Facilidad de obtención.
*Ocupar poca memoria.
Cualquiera que sea el método para generar números aleatorios debe
satisfacer las siguientes condiciones:
Deben ser:
1. Uniformemente distribuidos
2. Estadísticamente independientes
3. Reproducibles
4. Sin repetición dentro de una longitud determinada de la sucesión
5. Generación a grandes velocidades
6. Requerir el mínimo de capacidad de almacenamiento
fuente: http://es.scribd.com/doc/2557289/Numeros-Pseudoaleatorios
PRUEBA DE BONDAD DE AJUSTE DE DISTRIBUCIÓN UNIFORME POR KOLMOGOROV
METODOS DE GENERACION DE VARIABLES ALEATORIAS
Existen distintos métodos de generar variables aleatorias, cada uno de ellos se aplica a una serie de subconjuntos de distribución en los cuales funcione de manera más eficiente, los métodos son:
· Método de rechazo y aceptación
· Método de la transformada inversa
· Método de convolución
· Método de composición
METODO DE TRANSFORMADA INVERSA
El método de la transformada (o transformación) inversa, también conocido como método de la inversa de la transformada, es un método para la generación de números aleatorios de cualquier distribución de probabilidad continua cuando se conoce la inversa de su función de distribución (cdf). Este método es en general aplicable, pero puede resultar muy complicado obtener una expresión analítica de la inversa para algunas distribuciones de probabilidad. El método de Box-Muller es un ejemplo de algoritmo que aunque menos general, es más eficiente desde el punto de vista computacional.
- Distribucion exponencial
La función de distribución acumulada F(x) de la distribución exponencial está dada por:

Como F(x) se iguala a un número aleatorio A, entonces se debe despejar X


INSTRUCTIVO PARA GENERAR VARIABLES ALEATORIAS CON DISTRIBUCION EXPONENCIAL POR EL METODO DE LA TRANSFORMADA INVERSA
EJERCICIO EN EXCEL DE LA GENERACION DE VARIABLES ALEATORIAS CON DISTRIBUCION EXPONENCIAL POR EL METODO DE LA TRANSFORMADA INVERSA
MÉTODO DE CONVOLUCIÓN
La distribución de probabilidad de la suma de dos o más variables aleatorias independientes es llamada la convolución de las distribuciones de las variables originales. El método de convolución es entonces la suma de dos o más variables aleatorias para obtener una variable aleatoria con la distribución de probabilidad deseada. Puede ser usada para obtener variables con distribuciones Erlang y binomiales.
Además, muchas variables aleatorias incluyendo la normal, binomial, poisson, gamma, erlang, etc., se pueden expresar de forma exacta o aproximada mediante la suma lineal de otras variables aleatorias. El método de convolución se puede usar siempre y cuando la variable aleatoria x se pueda expresar como una combinación lineal de K variables aleatorias:
X= b1x1+b2x2+….bkxk
En este método se necesita generar k números aleatorios (u1, u2,..., uk) para generar (x1, x2,...xk) variables aleatorias usando alguno de los métodos anteriores y así poder obtener un valor de la variable que se desea obtener por convolución.
A continuación se dan unos ejemplos de aplicación de esta técnica:
· Una variable Erlang-k es la suma de k exponenciales.
· Una variable Binomial de parámetros n y p es la suma de n variable Bernoulli con probabilidad de éxito p.
· La chi-cuadrado con v grados de libertad es la suma de cuadrados de v normales N (0,1).
· La suma de un gran número de variables de determinada distribución tiene una distribución normal. Este hecho es usado para generar variables normales a partir de la suma de números U (0,1) adecuados.
· Una variable Pascal es la suma de m geométricas.
· La suma de dos uniformes tiene una densidad triangular.
Además, este método permite la interacción de variables aleatorias para realizar un tipo de distribución. En el caso de la distribución uniforme la fórmula a utilizar sería la siguiente:
U(a, b) = a + (b-a) Aleatorio ()
En el caso de generación de números aleatorios uniformemente distribuidos:
{kind=link}
Fuente: GARCÍA RAFFI, L.M. SÁNCHEZ PÉREZ, Enrique A. FIGUERES MORENO, Miguel. PÉREZ PEÑALVER, María José. Matemáticas asistidas por ordenador MAO. EDITORIAL UNIVERSIDAD POLITÉCNICA DE VALENCIA. PÁG 221-222.
INSTRUCTIVO PARA UTILIZAR EL METODO DE CONVOLUCION EN LA DISTRIBUCION NORMAL
1. Se debe tener conocimiento de la media y desviación del proceso, producto o servicio para llevar a cabo la generación de valores
2. Tenido estos valores se procede a registrar en una hoja Excel la media y la desviación en X columna
3. Ahora se procede a registrar el numero de datos que se quiere generar como por ejemplo 400 datos se ristra del 1 al 400
4. En la columna siguiente donde se registro las cantidades de datos a generar registramos otra con el nombre Media o Promedio
5. Luego se introduce la formula fundamental de todo este método que es la siguiente se introduce el símbolo igual luego toma la casilla donde está la media y la fija
6. Después suma la casilla donde está la desviación y se fija y la multiplicas por 12 veces la función aleatorio() donde los paréntesis se cierra sin nada dentro de ellos luego de haber digitado doce veces esta función se le resta el numero 6
7. Y se da entre para que arroje el primer valor aleatorio
8. Solo se tiene una casilla con un valor y se necesitan 400 datos, entonces a elegir esta casilla se lleva el cursor hasta la esquina izquierda de debajo de la casilla y se arrastra hasta el numero 400 y se suelta el curso ya se tiene 400 cantidades generadas aleatoriamente de una forma normal
9. ahora nos vamos a una casilla vacía cualquiera y se halla el promedio y la media de estos numero los cuales deben ser similar a la dada por el proceso, producto o servicio
A continuación se anexa un ejercicio por el método de convolucion aplicado a la distribución normal
Descargar ejercicio de Generación de variables aleatoris



METODO DE TRANSFORMADA INVERSA
El método de la transformada (o transformación) inversa, también conocido como método de la inversa de la transformada, es un método para la generación de números aleatorios de cualquier distribución de probabilidad continua cuando se conoce la inversa de su función de distribución (cdf). Este método es en general aplicable, pero puede resultar muy complicado obtener una expresión analítica de la inversa para algunas distribuciones de probabilidad. El método de Box-Muller es un ejemplo de algoritmo que aunque menos general, es más eficiente desde el punto de vista computacional.
La función de distribución acumulada F(x) de la distribución exponencial está dada por:
Como F(x) se iguala a un número aleatorio A, entonces se debe despejar X
SIMULACIÓN DE MONTECARLO
Muchas veces, es difícil calcular las probabilidades de ocurrencia de un evento, sin embargo se puede simular muchas veces los fenómenos en un ordenador y se aproxima; esto es lo que hace la simulación de Montecarlo, el cual es una serie de métodos estadísticos que usa secuencias de números aleatorios para realizar la modelación de los sistemas que están siendo analizados.
Cuando se conocen las funciones de densidad de probabilidad(PDF), se realiza un muestreo aleatorio del sistema, se hacen ensayos múltiples y se toma el promedio sobre el numero de observaciones, para las cuales se requiere que sean generados números aleatorios que estén distribuidos uniformemente en el intervalo de (0,1); los resultados deben ser acumulados o registrados apropiadamente para producir el resultado deseado.
1.
Se simulará un dado
La probabilidad teorica de cada cara del dado es de 1/6, para generar números aleatorios se tendrán en cuenta números de 0 a 1, dividiéndolo en 6 pedazos iguales

Fuente: imagen realizada por Martha Pulido

Con la generación del numero aleatorio se representara el lanzamiento de un dado, para lanzar el dado se debe presionar F9.
Ahora se representara en Excel, la probabilidad de que el dado caiga en cada una de las 6 caras, para ello se divide en 6 partes iguales, lo cual identificaremos con Limite inferior y limite superior, asignándole a cada intervalo un numero de cara, de la siguiente manera:

Ahora, se lanza el dado (con la tecla F9), y se identifica en que cara cayo con la función BUSCARV O CONSULTAV (dependiendo de la Version de Microsoft Excel que posea):

De manera que con esta función, se busca en la tabla de los limites inferiores, el numero aleatorio que dio, generando automáticamente la cara, en la imagen, C15 se refiere al numero aleatorio, C7: E12 a la tabla donde están los intervalos de números aleatorios y 3se refiere a la columna donde están las caras de los dados, que es la numero 3 en la matriz de los números aleatorios.
De esta forma se obtienen los lanzamientos del dado.
2. Si se quiere generar un sistema con condiciones uniformes, se puede generar números aleatorios entre un rango, por ejemplo tenemos:

Y quiero generar números entre ese rango, debo usar la función:ALEATORIO.ENTRE(), de lasiguiente forma:

Donde B21 y B22 son los limites A y B.
EJERCICIO DEL LANZAMIENTO DE 1 DADO
descargar ejercicio de simulacion del lanzamiento de 1 dado
EJERCICIO DEL LANZAMIENTO DE 1 DADO
descargar ejercicio de simulacion del lanzamiento de 1 dado
Ahora se explicara el ejercicio de Fritoabaja S.A. donde se tiene una serie de productos, con ciertos intervalos de demanda, con las cuales se quiere simular la probabilidad de perder dinero.
Primero se toma la tabla de productos y demanda:

Ahora, sacamos la demanda esperada así:

Ahora con el precio de ventas y el costo unitario de ventas se calcula el total de ventas, y luego el total de costos:


Ahora se calcula el total de ventas (sumatoria de las ventas), total de costos ( sumatorio de costos totales), la utilidad bruta(total de ventas – total de costos), suponiendo que los gastos administrativos de la organización son de $80000000.
Los gastos de publicidad varia entre los inervalos de 25000 000 a 50 000 000, por lo cual al evaluarlos se debe usar la función aleatorio.entre(limite superior: limite inferior.):

Por ultimo, se halla la Utilidad antes de Impuesto, solo restando la utilidad bruta – gastos administración y ventas – gastos de publicidad.
Ahora se generaran 100 utilidades antes de impuesto, para ver la perdida de 100 meses de la organización, se translada en el mes 1 la casilla H13 que corresponde a la utilidad antes de impuesto hallada:

Para generar las otras supuestas utilidades, se debe:
3. Seleccionar el rango en el cual se ubicaran las utilidades simuladas, nos vamos a datos, después se hunde Analisis y si
4. se le da click a la tabla de datos, en celda de entrada (fila) no se coloca nada, en las celdas de salida se coloca una casilla cualquiera,

5. despues se clickea en inicio, formato condicional, resaltar reglas de celdas, es menor que, se pone menor que 0, y se cambia el relleno a rojo claro para los números negativos o el formato que desee para diferenciar los números negativos de los positivos:


Los valores que aparecen con con relleno rojo, son los meses en los cuales la empresa tiene perdida, por lo cual el siguiente paso será calcular la venta promedio, que es la media de todas las ventas, es decir,

6. Ahora, se determinara la el total de los casos o el numero de los meses con la función CONTAR :

7. Se buscara la frecuencia observada de utilidades negativas o numero de perdidas con CONTAR.SI donde el rango serán las ventas y el criterio será que se contaran números menores que 0 de la siguiente forma:


En este caso, se muestra que el negocio gana, pero se tiene un nivel de riesgo donde de cada 100 meses que se haga el calculo de venta, se tendrá 12 meses de perdida y 88 de ganancias, es decir con una probabilidad del 12% de utilidades negativas.
EJERCICIO DEL MODELO DE FRITO ABAJA S.A.
SISTEMAS DE COLAS
sistemas de cola con un servidor
Cuando existe una gran demanda de un servicio, y este no puede ser satisfecho instantaneamente se forman esperas o colas, estas se ven desde la atencion en los establecimientos comerciales hasta el servicio publico.
se empezo a hablar de la teoria de colas en la decada de 1900's al implementar una teoria probabilistica para detereminar el numero optimo de lineas telefonicas en una centralita, teniendo en cuenta la frecuencia de las llamadas y su duracion, sentando asi, las bases para dicha teoria.
fuente: introduccion a la simulacion y a la teoria de colas.Ricardo Cao Abad
la prestacion del servicio tiene como minimo las siguientes caracteristicas:

fuente: imagen elaborada por Martha Pulido
Supongamos que el Banco Amigo tiene el periodo de 100 legadas de clientes, con un tiempo de servicio entre 15 y 25 minutos, distribuido uniformemente y un tiempo de llegada exponencial con media de 30 minutos, y solo cuenta con 1 cajero para atender
Primero se debe enumerar los 100 periodos de llegadas, luego para calcular los tiempos entre llegadas debido a que es exponencial , se aplica la formula

Es decir, en Excel:

Luego se arrastran todos los números, después que tenemos el tiempo entre llegadas, se calcula el tiempo de llegada, el tiempo de llegada del primer cliente, es por supuesto el generado en el primer tiempo entre llegada, sin embargo el del segundo es igual al del primer cliente mas el tiempo que demoro en llegar (tiempo entre llegada del cliente 2), por lo cual seria de la siguiente forma :
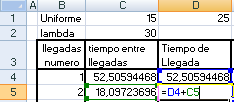
Y de esta forma se arrastra hasta el ultimo periodo. Ahora se calculara el inicio del tiempo de servicio, el inicio del tiempo de servicio en 1 sera igual al tiempo de llegada del cliente, cuando llega el segundo cliente este será atendido cuando uno de los clientes que esta en caja deje de ser atendido primero, por lo cual, este tiempo de inicio de servicio se deducirá de la siguiente forma

Se calcula el máximo tiempo entre el fin del servicio del primer cliente y el tiempo de llegada del segundo, representando este al momento en el cual el segundo cliente puede ser atendido por la caja.
A continuación se averiguara el tiempo de servicio, donde este tiene una distribución uniforme con un tiempo promedio entre 15 y 25, por lo cual se utiliza la función:

Donde C1 es 15 y C2 es 25, se arrastra la formula hasta el periodo 100, y se obtiene la totalidad de los tiempos de servicios, el siguiente paso es deducir el fin de los tiempos de servicio, que no es mas que la suma de el tiempo de inicio de servicio y el tiempo de servicio de cada cliente.
Ahora se averiguara el tiempo que pasa el cliente en cola o espera, es decir , el tiempo en línea; para ello simplemente se resta el inicio del tiempo de servicio de cada cliente y el tiempo en que este llego de la siguiente forma:

se calcula el tiempo total del sistema, que seria la sustracción entre el fin tiempo de servicio y el tiempo de llegada de cada uno de los clientes.
Ahora se quiere saber el numero de clientes que hay en cola, por lo cual se debe saber a que cliente se esta atendiendo y restar el ultimo cliente que ha llegado menos el atendido, y de esta forma deducir cuantas personas esperan, para ello se aplicara la función buscar V, donde esta examinara en el tiempo de llegada el valor que se encuentra en fin tiempo de servicio de la posición actual, al encontrarla, tomara el numero de llegada correspondiente a la posición encontrada y se la restara a la posición actual, de la siguiente forma:

Donde el valor numero 1 que esta en azul se busca en el rango subrayado de verde en la columna de tiempo de llegada, la función toma el valo que esta al lado que en este caso es 2 (dentro de una circunferencia amarilla), representando al cliente 2, y le resta la posición actual que en este caso es 1, por lo cual hay una persona esperando a ser atendida.
Para saber cuantas personas hay en el sistema, se le suma 1 (porque es un cajero), al numero de personas en cola.
A continuación esta el caso del banco amigo para descargar en excel:
ejercicio de simulacion por excel con un cajero
Ahora supongamos que el Banco tiene 2 cajeros para atender
Primero se debe enumerar los 100 periodos de llegadas, luego para calcular los tiempos entre llegadas debido a que es exponencial , se aplica la formula

Es decir, en Excel:

Luego se arrastran todos los números, después que tenemos el tiempo entre llegadas, se calcula el tiempo de llegada, el tiempo de llegada del primer cliente, es por supuesto el generado en el primer tiempo entre llegada, sin embargo el del segundo es igual al del primer cliente mas el tiempo que demoro en llegar (tiempo entre llegada del cliente 2), por lo cual seria de la siguiente forma :

Y de esta forma se arrastra hasta el ultimo periodo. Ahora se calculara el inicio del tiempo de servicio, como se cuenta con 2 cajeros , el inicio del tiempo de servicio en 1 y en 2 sera igual al tiempo de llegada del primer y del segundo cliente, cuando llega el tercer cliente este será atendido cuando uno de los clientes que esta en caja deje de ser atendido primero, por lo cual, este tiempo de inicio de servicio se deducirá de la siguiente forma:

Se calcula el minimo de los fin de tiempos de servicio entre 1 y 2, pero este será atendido teniendo en cuenta su tiempo de llegada, porque si por ejemplo se ha dejado de atender al cliente 2 y el cliente 3 no ha llegado, este no puede ser atendido hasta que llegue al sistema.
A continuación se averiguara el tiempo de servicio, donde este tiene una distribución uniforme con un tiempo promedio entre 15 y 25, por lo cual se utiliza la función:

Donde C1 es 15 y C2 es 25, se arrastra la formula hasta el periodo 100, y se obtiene la totalidad de los tiempos de servicios, el siguiente paso es deducir el fin de los tiempos de servicio, que no es mas que la suma de el tiempo de inicio de servicio y el tiempo de servicio de cada cliente.
Ahora se averiguara el tiempo que pasa el cliente en cola o espera, es decir , el tiempo en línea; para ello simplemente se resta el inicio del tiempo de servicio de cada cliente y el tiempo en que este llego de la siguiente forma:

Por ultimo, se calcula el tiempo total del sistema, que seria la sustracción entre el fin tiempo de servicio y el tiempo de llegada de cada uno de los clientes.
A continuación esta el caso del banco amigo para descargar en excel: